Before working at CUNY, I occasionally made back-of-the-book indexes for books in religious studies, anthropology and gender studies. Indexing is fun, though very time-consuming work. It doesn’t make much money, but it’s gratifying and interesting.
I feel that indexing is a field with a lot of potential. Building conceptual maps of book-length texts is, in my opinion, very useful work. But book indexing is a profession that has its problems. Many of these have to do with technology. Most indexers rely on niche software tools that are easy to use but are often de-skilling. Our dependence on these tools contributes to the perception that indexing is low-value work.
Rather than rely on vendors, indexers could build their own tools to support their indexing. We could write and open source code to move the profession forward. To make this point using a concrete example, I built a sample index visualization tool:
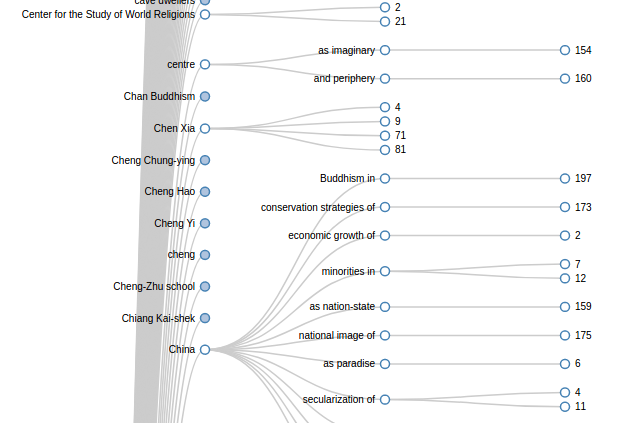
Click the image to try it out.
The point is not that this tool is particularly sophisticated (it’s not), nor that it’s particularly novel (also not). Instead, its rhetorical agenda is that it is made by a (former) indexer and is open sourced for other indexers. It’s a very modest effort, but my point is to suggest that if indexers prioritized open source work, we’d be much further along in developing our tools and our skill sets.